Futarchy: Governance for AI Development Using Prediction Markets and Community Feedback

1. Introduction
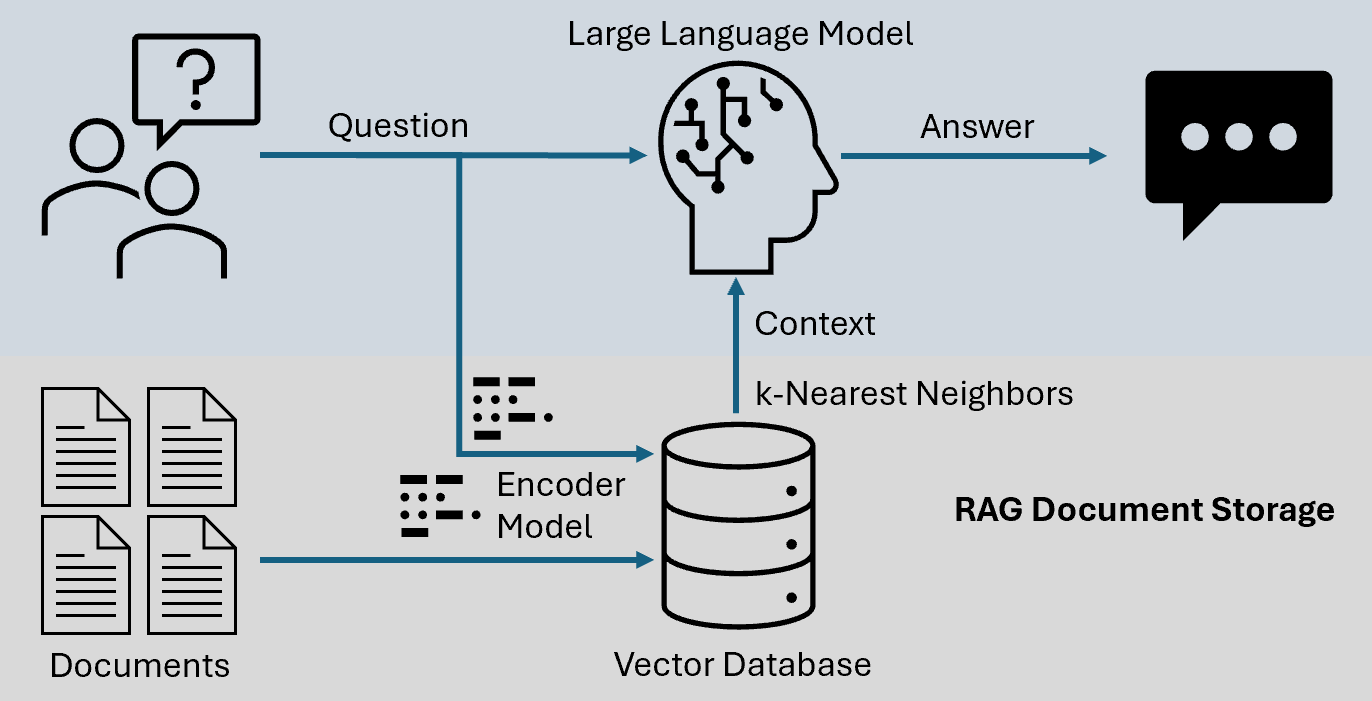
AI development today faces a dual challenge: models are growing ever more complex, yet aligning them with human needs requires extensive oversight and feedback. Fission’s DeSAi framework (Decentralized Science + AI) addresses this by combining advanced model optimization techniques with large-scale human feedback loops (e.g., Reinforcement Learning from Human Feedback, RLHF) and community-driven governance. The central question, however, is how to incentivize and coordinate these decentralized feedback processes effectively.
Fission’s answer is Futarchy—a governance model in which communities do not simply vote on proposals, but instead bet on which proposals will best fulfill a shared success metric. By rewarding accurate predictions and penalizing mistaken ones, Futarchy taps into collective expertise to guide strategic decisions. This research report explores how Futarchy can be applied to optimize AI development and deployment within the DeSAi paradigm. Specifically, it will:
- Define Futarchy and its Core Mechanics Explain how prediction markets function in an on-chain governance context.
- Apply Futarchy to AI Optimization Examine how conditional markets can shape AI model improvements through community feedback and economic incentives.
- Discuss Technical Implementation Detail the use of decentralized oracles, time-weighted average price (TWAP) mechanisms, and other features needed for reliable performance tracking.
- Outline a Hybrid Rollout Strategy Propose steps for transitioning from off-chain or advisory market trials to fully on-chain Futarchy, ensuring stakeholder trust and participation.
- Review Key Case Studies Highlight real-world experiments—such as Augur, GnosisDAO, and more recent initiatives—that demonstrate both the potential and challenges of futarchic governance.
- Identify Risks and Mitigations Analyze common pitfalls—market manipulation, low liquidity, poorly chosen metrics—and discuss safeguard techniques.
- Present an End-to-End Futarchy Flow Illustrate how proposals move from initial community submission to on-chain market assessment, model implementation, and verified outcomes.
- Conclude with a Vision for AI Governance Summarize how Futarchy can become a transformative model for AI governance and offer insights on practical adoption.
Throughout, we maintain a focus on aligning AI development with community values—“vote on values, but bet on beliefs,” in the spirit of Futarchy’s guiding principle. By leveraging prediction markets and decentralized participation, Fission’s approach seeks to ground each model update and research decision in real data and collective expertise, rather than top-down judgment or speculation. This synergy can lead to a more transparent, accountable, and ultimately more effective path forward for AI.