Retrieval Augmented Generation : A Critical Tool for Managing and Selecting Dataset in Web3
Retrieval-Augmented Generation (RAG): A Critical Tool for Managing and Selecting Datasets in Decentralized Data Labeling
In the evolving landscape of artificial intelligence (AI), data is the lifeblood of innovation. As the field transitions toward decentralized data labeling frameworks to address biases and enhance diversity, the challenge of managing and selecting datasets becomes paramount. Retrieval-Augmented Generation (RAG) emerges as a transformative solution, combining retrieval mechanisms with generative models to optimize data utilization and improve the quality of AI systems. This blog explores the concept of RAG, its role in decentralized labeling, and why it is essential for dataset management.
Understanding Retrieval-Augmented Generation (RAG)
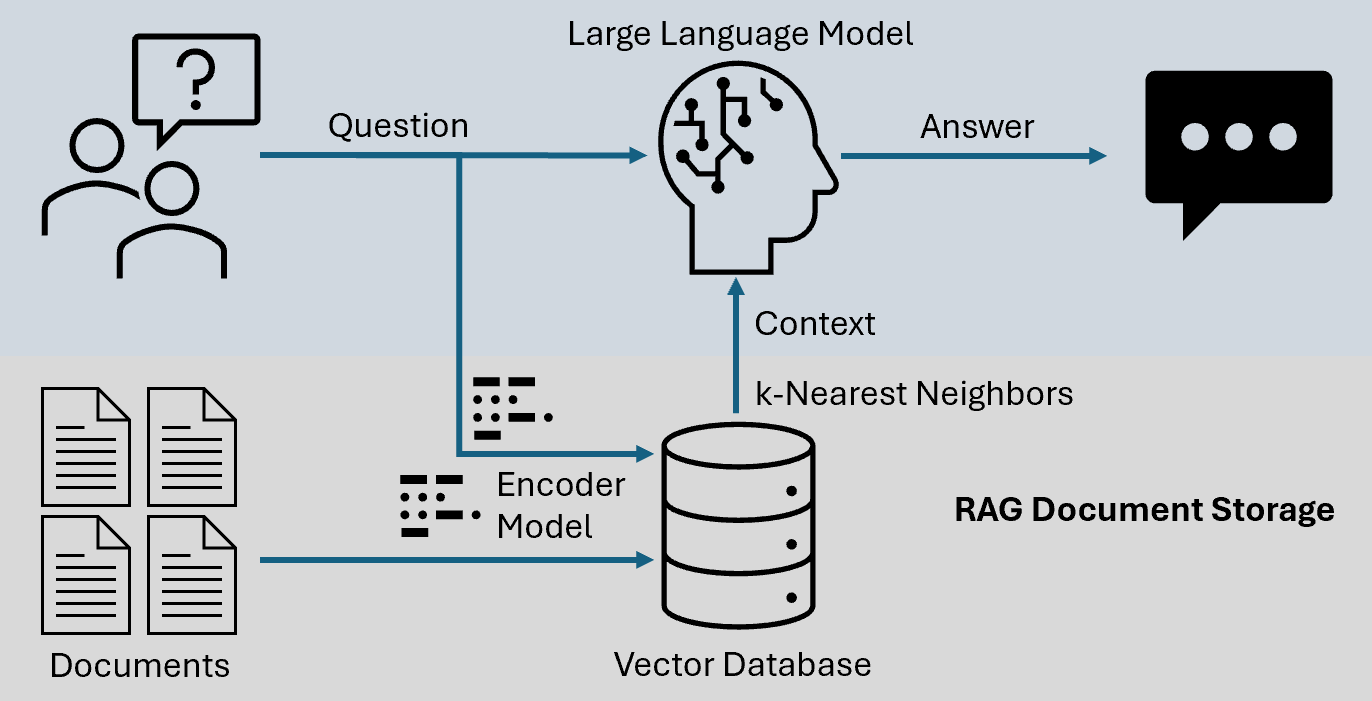
RAG is a hybrid approach that integrates information retrieval with generative AI models. Unlike standalone generative models, which rely entirely on pre-trained data, RAG systems retrieve relevant external data to enhance the generation process. This method combines the strengths of retrieval systems, such as search engines, with the creative potential of generative models, enabling:
- Context-Aware Generation: By pulling in relevant external knowledge, RAG can generate responses or insights that are more accurate and grounded in factual data.
- Dynamic Adaptation: The ability to retrieve real-time or updated information ensures that models remain relevant and effective.
- Enhanced Diversity: By sourcing data from decentralized and diverse repositories, RAG systems mitigate biases inherent in single-source datasets.
The Need for RAG in Decentralized Data Labeling
As decentralized labeling frameworks gain traction, they introduce unique challenges in dataset management:
- Diverse Data Sources: Decentralized systems aggregate data from multiple sources, leading to variability in quality, structure, and annotations. RAG can effectively manage this diversity by retrieving the most relevant and high-quality subsets for specific tasks.
- Bias Mitigation: Centralized systems often suffer from inherent biases due to limited annotator perspectives or standardized labeling processes. RAG’s retrieval mechanisms enable the identification and inclusion of underrepresented data, promoting fairness and equity in AI systems.
- Scalability: The volume of data in decentralized systems can be overwhelming. RAG provides a scalable solution by prioritizing and selecting only the most critical data points, reducing computational overhead while maintaining performance.
How RAG Works in Decentralized Labeling
- Dataset Retrieval: RAG systems query decentralized repositories to retrieve relevant datasets based on task-specific criteria. For example, a medical AI application might retrieve labeled X-ray images from distributed hospital databases.
- Knowledge Integration: Retrieved data is fed into a generative model, which uses this external knowledge to produce informed and contextually accurate outputs. In decentralized labeling, this could mean generating guidelines for annotators based on retrieved metadata.
- Feedback Loop: The outputs generated by RAG are validated and refined through a feedback loop, ensuring alignment with decentralized labeling objectives.
Benefits of RAG for Decentralized Data Labeling
- Improved Annotation Quality: By retrieving the most relevant data, RAG ensures that annotations are contextually accurate and representative.
- Enhanced Efficiency: Automating the dataset selection process reduces manual overhead and accelerates labeling timelines.
- Transparency and Accountability: RAG systems can log retrieval sources, enabling audit trails and ensuring accountability in decentralized labeling frameworks.
- Dynamic Updates: As data repositories evolve, RAG can adapt by retrieving the latest and most relevant information, keeping labeling processes up to date.
Challenges and Future Directions
While RAG presents significant advantages, it also introduces challenges:
- Computational Overheads: The integration of retrieval mechanisms can increase system complexity and computational requirements.
- Data Privacy: Retrieving data from decentralized sources raises concerns about privacy and compliance, especially in sensitive domains like healthcare.
- Trustworthiness of Sources: Ensuring the reliability of retrieved datasets is critical to maintaining the integrity of labeling processes.
Future research should focus on:
- Developing privacy-preserving retrieval techniques.
- Enhancing retrieval algorithms to prioritize trustworthy sources.
- Creating frameworks for seamless integration of RAG in decentralized systems.
Conclusion
Retrieval-Augmented Generation is a game-changing approach for managing and selecting datasets in decentralized data labeling. By bridging retrieval and generation, RAG addresses critical challenges such as bias, scalability, and diversity in dataset management. As decentralized frameworks continue to redefine AI development, integrating RAG will be pivotal in ensuring robust, equitable, and efficient AI systems.
Reference
- Improving Multi-Modal Learning:
- Research by Chen et al. (2024) highlights the challenges of multi-modal alignment in large language models. RAG’s retrieval capabilities allow models to access structured annotations dynamically, mitigating the "multi-modal alignment tax."
- Bias Detection and Mitigation:
- Zeng (2024) demonstrated how decentralized frameworks using RAG identified biases in labeled clock images. By retrieving diverse datasets, the system was able to generate more balanced annotations.
- Optimizing Data Validation:
- Studies on collaborative labeling platforms, such as those by OpenAI and Meta AI Labs, show how RAG reduces inconsistencies by retrieving cross-referenced data for annotation validation.