Hybrid Search : Spare + Dense RAG
Why We Use Hybrid Search RAG (Sparse + Dense Embedding + ReRanker) Instead of Naive RAG
Problem Statement: Decentralized Web3 Agents and the Need for Efficient Data Retrieval
The emergence of decentralized Web3 agents has redefined the landscape of AI-driven automation. Unlike traditional centralized frameworks, these agents operate on decentralized platforms, emphasizing transparency, user ownership, and multi-modal data processing. However, managing and retrieving data in decentralized environments poses unique challenges:
- Data Fragmentation: Information is scattered across multiple decentralized nodes, making efficient retrieval complex.
- Diverse Data Modalities: Web3 agents require access to text, images, and structured metadata to function effectively.
- Performance Bottlenecks: Standard retrieval mechanisms struggle with scalability and semantic understanding in decentralized systems.
This is where Hybrid Search RAG—a sophisticated blend of sparse and dense embedding retrieval with re-ranking—becomes a game-changer. It not only addresses these challenges but also sets a new benchmark for data retrieval in decentralized frameworks.
What is Naive RAG?
Naive RAG integrates a generative AI model with a retrieval component that fetches relevant documents from a database. This retrieval is typically based on:
- Sparse Embeddings: Techniques like TF-IDF or BM25 for keyword-based matching (Robertson, S. et al., 2009).
- Dense Embeddings: Vectorized representations using deep learning models like Sentence Transformers (Reimers & Gurevych, 2019) or BERT (Devlin et al., 2018).
While effective for basic applications, naive RAG has critical shortcomings:
- Limited Context Understanding: Sparse embeddings often fail to capture semantic nuances, especially in multi-modal data.
- Suboptimal Ranking: Dense embeddings can retrieve irrelevant documents due to lack of fine-grained ranking mechanisms.
- Scalability Issues: Naive implementations struggle to efficiently handle large-scale or multi-modal datasets.
The Hybrid Search RAG Advantage
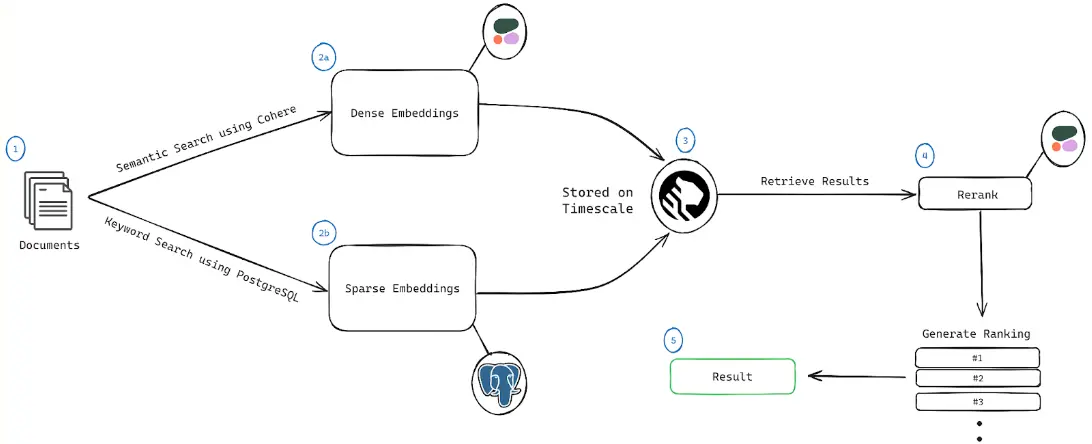
Hybrid Search RAG addresses these limitations by combining:
- Sparse Embedding Retrieval: Captures lexical-level matches for high-precision retrieval (Manning, C. et al., 2008).
- Dense Embedding Retrieval: Captures semantic-level matches for high-recall retrieval (Karpukhin et al., 2020).
- Re-Ranking Models: Ranks retrieved documents using contextual and task-specific scoring mechanisms (Nogueira & Cho, 2019).
This hybrid approach ensures that retrieved documents are both semantically relevant and contextually precise.
Key Advantages:
- Improved Accuracy: By integrating sparse and dense retrieval, Hybrid RAG achieves superior precision and recall.
- Contextual Relevance: Re-ranking models ensure that retrieved documents align with the generative model’s requirements.
- Multi-Modal Support: Hybrid RAG excels in environments with diverse data types (text, images, etc.), a necessity for modern applications.
Why Milvus?
Hybrid Search RAG’s effectiveness is amplified by robust database technologies like Milvus, a leading multi-modal vector database. Milvus supports both sparse and dense vector indexing, making it an ideal choice for hybrid retrieval systems.
Key Features of Milvus:
- Multi-Modal Support: Seamlessly handles text, image, and other data types, aligning perfectly with Hybrid RAG requirements.
- Scalability: Designed for large-scale applications, Milvus ensures efficient storage and retrieval even with billions of vectors.
- Integration Flexibility: Supports hybrid search mechanisms natively, reducing the complexity of system integration.
- Performance Optimization: Advanced indexing techniques ensure low-latency query responses.
By adopting Milvus, we unlock the full potential of Hybrid Search RAG, ensuring scalability, speed, and adaptability for cutting-edge AI applications.
Real-World Applications
1. Customer Support Chatbots:
- Hybrid RAG ensures that responses are contextually precise, even for multi-turn conversations.
2. Web3 Document Retrieval:
- Provides accurate and diverse references from structured and unstructured datasets, critical for diagnostic AI.
3. E-Commerce Search:
- Improves product recommendation systems by understanding both semantic and lexical queries.
Why Our Technology is the Future
By adopting Hybrid Search RAG powered by Milvus, we are pioneering a new standard in AI frameworks. This approach:
- Bridges the gap between traditional and advanced AI retrieval methods.
- Unlocks new possibilities for multi-modal applications.
- Ensures adaptability and scalability for future AI systems.
Our technology is not just an upgrade; it’s a paradigm shift that transforms what RAG-based frameworks can achieve, propelling the field into a new era of innovation.
References
- Robertson, S. et al. (2009): "The Probabilistic Relevance Framework: BM25 and Beyond." Link
- Reimers, N. & Gurevych, I. (2019): "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks." Link
- Devlin, J. et al. (2018): "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding." Link
- Manning, C. et al. (2008): "Introduction to Information Retrieval." Link
- Karpukhin, V. et al. (2020): "DPR: Dense Passage Retrieval for Open-Domain Question Answering." Link
- Nogueira, R. & Cho, K. (2019): "Passage Re-Ranking with BERT." Link
- Milvus Documentation: "Hybrid Search and Multi-Modal Database Features." Link
Explore our framework today and join the revolution in AI retrieval systems!