Biased Data - Centralized Cause
Introduction
The rapid advancement of artificial intelligence (AI) technologies, particularly large language models like GPT-4 and its successors, has brought to light significant challenges in data labeling, training, and model performance. This report highlights the critical issues of biased data labeling, inadequate datasets, and the consequential limitations in AI model performance. Through case studies, performance comparisons, and references to industry reports, this paper emphasizes why high-quality, unbiased data is essential for improving AI capabilities.
Biased Data Labeling: A Persistent Problem
One of the most significant challenges in AI training is biased data labeling, a process heavily reliant on human workers. For instance, OpenAI has previously faced criticism for employing low-cost labor in Kenya to label data for its safety protocols. According to a Time report, these workers labeled datasets necessary for identifying and moderating harmful content. While effective in establishing safety standards, the reliance on low-cost labor raises concerns about the consistency and fairness of the labels.
Additionally, repetitive word usage in AI outputs further demonstrates labeling bias. For example, Paul Graham, a notable tech entrepreneur, tweeted about a cold email using the word "delve," highlighting GPT's over-reliance on specific phrases. This repetitive behavior may stem from biases ingrained during the training phase, where certain words or patterns are disproportionately represented in datasets. Reddit users have pointed out that such quirks reduce the model's effectiveness as a writer, resulting in formulaic and less persuasive text.
Many AI companies claim they have sufficient data for training future-generation models. For example, Sam Altman, CEO of OpenAI, stated in an interview that OpenAI has "enough data" to develop its next-generation AI systems (source). However, recent technical reports and performance comparisons suggest otherwise.
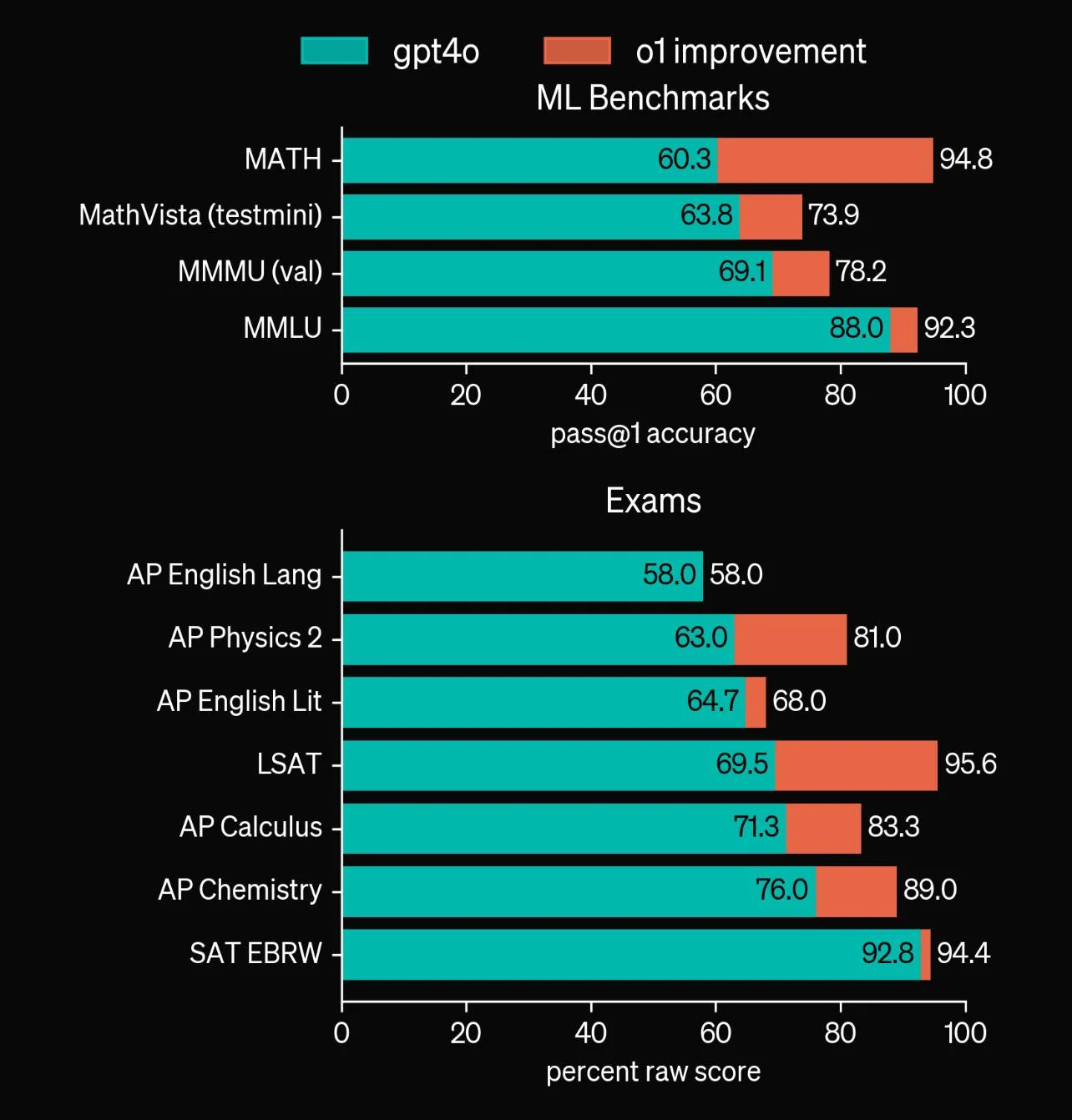
The accompanying visualizations, such as the performance difference between GPT-4o and GPT-o1, indicate limited progress in key areas. While GPT-o1 demonstrates significant improvements in some benchmarks, it struggles in domains like mathematics, a field where state-of-the-art (SOTA) AI models consistently underperform.
The comparative analysis of AI models reveals persistent performance gaps. For instance:
This underlines the fact that existing datasets may be insufficient in diversity and quality, particularly for specialized tasks like mathematical reasoning (arXiv study).
- Mathematical Reasoning: GPT-o1 achieved only marginal improvements in pass@1 accuracy on math-related benchmarks, reflecting broader challenges in training AI for complex logical reasoning.
- Examination Results: The chart comparing GPT-4o and GPT-o1 performance on various exams shows uneven progress. While improvements are evident in some subjects (e.g., AP Physics 2 and AP Chemistry), other areas, such as English language tasks, show minimal advancement.
These disparities indicate that the training datasets lack the depth and specificity needed to drive consistent improvements across domains.
Implications of Biased and Insufficient Data
The problems of biased labeling and insufficient data have far-reaching implications. AI models trained on subpar datasets exhibit predictable, formulaic outputs and fail to generalize effectively across tasks. Moreover, the conditions under which data labeling occurs can influence the quality of annotations, leading to systemic biases in the model's predictions.
Reddit discussions and interviews with experts further highlight the underlying issue: companies often prioritize cost efficiency over the quality of labeling processes. This results in "nerfed" models that fail to meet their full potential. For example, GPT-4o's minimal improvements in English language tasks suggest that the model is nearing saturation in specific areas, potentially due to inherent biases in the dataset or limitations in training methodologies.
Examples of AI Model Inaccuracy connected with Biased Dataset
-
Visual Hallucinations in Multimodal AI Models
Research by Lu (2024) examines the phenomenon of visual hallucinations in multimodal AI models, particularly in how large language models (LLMs) interpret visually deceptive images. While these models may excel in standard visual recognition tasks, their performance significantly deteriorates when encountering deceptive inputs. This highlights a substantial gap in their reliability and underscores the need for more robust, unbiased training datasets to improve accuracy (source).
-
Challenges in Detecting Hallucinations
Gunjal (2024) delves into the difficulties of identifying and mitigating hallucinations in large vision-language models (LVLMs). The study attributes hallucinations to the models' inability to effectively reference or describe input images, pointing to a critical need for integrating visual context to reduce inaccuracies. This demonstrates the importance of comprehensive and unbiased labeling to address such deficiencies (source).
-
Limitations of Visual Understanding
Huang et al. (2024) provide a survey on hallucinations in LLMs, identifying their limitations in processing visual inputs as a primary reason for generating plausible yet incorrect outputs. This issue becomes particularly pronounced in tasks demanding precision, such as reading clocks or performing mathematical calculations based on visual data. The findings reinforce the necessity of high-quality, diverse datasets to enhance model accuracy in visual reasoning tasks (source).
-
Mixed-Type Data Challenges
A study in JAMA Network Open highlights the difficulties AI models face when dealing with datasets combining text and image modalities. The findings suggest that current AI systems are not adept at handling mixed data types, further emphasizing the need for larger, better-labeled datasets to train models capable of processing multimodal information accurately (source).
Evidence Shows Correlation Between Non Public group with Biased Datasets
-
Bias in Inferring Psychological Dispositions
Peters et al. (2024) explore how LLMs infer psychological traits of social media users and find that these models are prone to stereotyping based on demographic and geographic data. The research suggests that biases in the training dataset are reflected in the model’s outputs, potentially leading to hallucinations or outputs that reinforce stereotypes. This highlights the importance of using diverse and unbiased datasets to mitigate these issues (source).
-
Perceptual Inference and Top-Down Biases
Cassidy et al. (2018) examine perceptual inference mechanisms linked to hallucinations, proposing that top-down cognitive biases can influence the prevalence of hallucinations in controlled group settings. While this study is rooted in medical neuroscience, its implications for AI training are significant: controlled datasets that lack diversity may inadvertently reinforce existing biases, leading to distorted outputs. This reinforces the need for broader datasets and labeling practices to avoid such pitfalls (source). Recent advancements in understanding generative AI through the lens of human neuroscience further underscore the relevance of this study.